Python이 뒤에서 데이터를 어떻게 처리하는지 궁금해 본 적이 있나요?
변수는 어떻게 메모리에 저장되나요? 언제 삭제되나요?
이 글에서는 Python이 메모리 관리를 어떻게 처리하는지 이해하기 위해 Python의 내부에 대해 자세히 알아보겠다.
이 글를 통해 다음과 같은 내용을 얻을 수 있다.
- 메모리와 관련된 로우 레벨 컴퓨팅에 대해 자세히 알아보기
- Python이 하위 수준의 운영을 추상화하는 방법 이해
- Python의 내부 메모리 관리 알고리즘에 대해 알아보기
- 또한 Python의 내부 정보를 이해하면 Python의 일부 동작에 대한 더 나은 통찰력을 얻을 수 있다.
- 파이썬에 대한 새로운 느낌을 얻길 바란다. 우리의 프로그램이 우리가 기대하는 대로 작동하도록 보장하기 위해 많은 연산이 뒤에서 일어나고 있다.
메모리는 빈 책이다
우리는 컴퓨터의 메모리를 단편 소설을 위한 빈 책으로 생각하는 것으로 시작할 수 있다. 아직 페이지에는 아무것도 쓰여 있지 않는다. 작가들이 글을 쓰기 시작 할 것이고 각 작가는 그들의 이야기를 쓸 수 있는 공간을 원한다.
작가들의 글은 서로 덮어쓰는 것이 허용되지 않기 때문에, 그들은 그들이 어떤 페이지를 쓰는지에 대해 주의해야 한다. 집필을 시작하기 전에, 그들은 책의 매니저와 상의하기 시작한다. 그리고 나서 매니저는 그들이 책에서 쓸 수 있는 곳을 결정한다.
만약 책은 오랫동안 쓰여진 경우, 그 안에 있는 많은 이야기들은 더 이상 새로운 이야기와 관련이 없을 수 있다. 아무도 그 이야기들을 읽거나 참조하지 않을 때, 새로운 이야기들을 위한 공간을 만들기 위해 제거된다.
본질적으로, 컴퓨터 메모리는 그 빈 책과 같다. 사실, 메모리 페이지의 고정 길이 연속 블록을 부르는 것은 흔한 일이기 때문에 이 비유는 꽤 잘 통힌다.
작가는 메모리에 데이터를 저장해야 하는 다른 응용 프로그램이나 프로세스와 같다. 작가들이 책에서 쓸 수 있는 곳을 결정하는 매니저는 일종의 메모리 관리자 역할을 한다. 새로운 이야기들을 위한 공간을 만들기 위해 오래된 이야기들을 지운 사람은 가비지 컬렉터이다.
메모리 관리: 하드웨어에서 소프트웨어로
메모리 관리는 응용 프로그램이 데이터를 읽고 쓰는 프로세스이다. 메모리 관리자는 응용 프로그램의 데이터를 저장할 위치를 결정한다. 우리의 책에 비유한 페이지들처럼 제한된 메모리 덩어리가 있기 때문에, 매니저는 약간의 여유 공간을 찾아서 그것을 응용 프로그램에 제공해야 한다. 메모리를 제공하는 이러한 과정을 일반적으로 메모리 할당이라고 한다.
한편, 데이터가 더 이상 필요하지 않을 경우 데이터를 삭제하거나 해제할 수 있다. 하지만 어디로 갈까? 이 “메모리"는 어디서 온 것일까?
컴퓨터 어딘가에 Python 프로그램을 실행할 때 데이터를 저장하는 물리적 장치가 있다. 그러나 파이썬 코드는 객체가 실제로 하드웨어에 도달하기 전에 많은 추상화 계층을 거친다.
하드웨어(예: RAM 또는 하드 드라이브) 위의 주요 계층 중 하나는 운영 체제(OS)이다. 메모리 읽기 및 쓰기 요청을 수행하거나 거부한다.
OS 위에는 애플리케이션이 있는데, 그 중 하나가 기본 Python 구현 응용 프로그램(OS에 포함되거나 python.org에서 다운로드됨)이다. Python 코드에 대한 메모리 관리는 Python 애플리케이션에서 처리한다. Python 애플리케이션이 메모리 관리를 위해 사용하는 알고리즘과 구조가 이 글의 주제이다.
기본 Python 구현
기본 파이썬 구현체인 CPython은 실제로 C 프로그래밍 언어로 작성된다.
파이썬 언어는 영어로 작성된 참조 매뉴얼에 정의되어 있다. 하지만, 설명서가 그렇게 유용하지는 않다. 매뉴얼에 있는 규칙에 따라 작성된 코드를 해석할 수 있는 무언가가 여전히 필요하다.
또한 컴퓨터에서 실제로 해석된 코드를 실행할 수 있는 무언가가 필요하다. 기본 Python 구현은 이러한 요구 사항을 모두 충족한다. Python 코드는 가상 머신에서 실행되는 명령으로 변환한다.
참고: 가상 시스템은 물리적 컴퓨터와 비슷하지만 소프트웨어로 구현됩니다. 일반적으로 어셈블리 instructions과 유사한 기본 instructions을 처리합니다.
파이썬은 인터프리터 프로그래밍 언어이다. 우리의 파이썬 코드는 실제로 바이트코드라고 불리는 컴퓨터에서 읽을 수 있는 명령어로 컴파일된다. 이러한 instructions은 코드를 실행할 때 가상 시스템에 의해 해석된다.
.pyc 파일이나 _pycache 폴더를 본 적이 있나요? 가상 머신에 의해 해석되는 바이트 코드입니다.
CPython 이외 구현도 있다는 점을 유념해야 한다. IronPython은 마이크로소프트의 공통 언어 런타임에서 실행되도록 컴파일된다. Jython은 자바 가상 머신에서 실행할 자바 바이트 코드로 컴파일된다. 그리고 PyPy도 있다.
주의 사항: 이 문서의 참조 버전은 파이썬 3.7입니다.
네, CPython은 C로 작성되고, Python 바이트코드를 해석한다. 이것이 메모리 관리와 무슨 관계가 있습니까? 메모리 관리 알고리즘과 구조는 C의 CPython 코드에 존재한다. 파이썬의 메모리 관리를 이해하려면 CPython 자체에 대한 기본적인 이해를 해야 한다.
CPython은 객체 지향 프로그래밍을 기본적으로 지원하지 않는 C로 작성된다. 그 이유로 CPython 코드에는 꽤 많은 흥미로운 디자인이 있다.
당신은 파이썬의 모든 것이 객체이며 심지어 int나 str과 같은 유형이라는 것을 들어봤을 것이다. CPython의 구현 수준에서는 사실이다. PyObject라고 불리는 구조가 있는데, CPython의 다른 모든 물체는 이것을 사용한다.
참고: C의 구조체는 서로 다른 데이터 유형을 그룹화하는 사용자 지정 데이터 유형입니다. 객체 지향 언어와 비교하자면, 이것은 속성이 있고 메서드가 없는 클래스와 같습니다.
PyObject는 파이썬의 모든 객체 중 가장 큰 것으로, 두 가지만 포함하고 있다.
- ob_refcnt: 참조 수
- ob_type: 다른 유형의 포인터
참조 카운트는 가비지 수집에 사용된다. 그러면 실제 개체 유형에 대한 포인터가 있다. 이 개체 유형은 Python 개체를 설명하는 또 다른 구조체일 뿐이다(예: dict 또는 int).
각 개체에는 해당 개체를 저장할 메모리를 얻는 방법을 아는 고유한 개체별 메모리 할당자가 있다. 각 개체는 또한 더 이상 필요하지 않은 메모리를 “해제” 하는 개체별 메모리 할당 해제기를 가지고 있다.
하지만, 그 전에 생각해야할 중요한 요소가 있다. 메모리는 컴퓨터의 공유 리소스이며, 서로 다른 두 프로세스가 동시에 동일한 위치에 쓰려고 할 경우 무시무시한 일이 발생할 수 있다.
글로벌 인터프리터 잠금 장치(GIL)
GIL은 컴퓨터의 메모리와 같은 공유 리소스를 처리하는 일반적인 문제에 대한 해결책이다. 두 개의 스레드가 동시에 동일한 리소스를 수정하려고 할 때 서로의 발가락을 밟을 수 있다. 최종 결과는 두 실 모두 원하는 것으로 끝나지 않는 왜곡된 혼란일 수 있다.
책의 비유에 대해 다시 생각해 보자. 두 작가가 무조건 지금이 자신의 집필 차례라고 결정했다고 가정해보자. 그뿐만 아니라 두 사람 모두 동시에 같은 페이지에 글을 써야 할 수도 있다.
그들은 각자 이야기를 꾸며내려는 상대방의 시도를 무시하고 그 페이지에 글을 쓰기 시작한다. 최종 결과는 두 개의 글이 서로 겹쳐져 있고 전체 페이지를 완전히 읽을 수 없게 만든다.
이 문제에 대한 한 가지 해결책은 스레드가 공유 자원(책의 페이지)과 상호 작용할 때 인터프리터에 대한 단일 전역 잠금이다. 즉, 한 번에 한 명의 작가만 쓸 수 있는 것이다.
Python의 GIL은 전체 인터프리터를 잠그는 것으로 이를 달성하는데, 이는 다른 스레드가 현재 인터프리터를 밟는 것은 불가능하다는 것을 의미한다. CPython은 메모리를 처리할 때 GIL을 사용하여 안전하게 메모리를 처리한다.
가비지 컬렉션
책의 비유에 대해 다시 한번 생각해보고 책에 나오는 이야기들 중 일부가 아주 오래되고 있다고 가정해보자. 아무도 그 이야기들을 더 이상 읽거나 참고하지 않는다. 만약 아무도 어떤 것을 읽거나 자신의 작품에서 그것을 참조하지 않는다면, 그 이야기를 없애서 새로운 글쓰기를 위한 공간을 만들 수 있을 것이다.
참조되지 않은 오래된 쓰기는 참조 카운트가 0으로 떨어진 파이썬의 개체와 비교할 수 있다. Python의 모든 개체에는 참조 수와 유형에 대한 포인터가 있다.
참조 카운트는 몇 가지 다른 이유로 증가한다. 예를 들어, 기준 카운트를 다른 변수에 할당하면 기준 카운트가 증가한다.
| |
개체를 인수로 전달할 경우에도 증가한다.
| |
마지막 예로, 객체를 목록에 포함하면 참조 카운트가 증가한다.
| |
Python을 사용하면 시스템 모듈을 사용하여 개체의 현재 참조 수를 검사할 수 있다. sys.getrefcount(numbers)를 사용할 수 있지만 개체를 전달하여 refcount()를 가져오면 기준 카운트가 1씩 증가한다.
어떤 경우에도 개체가 코드에서 계속 존재해야 하는 경우 참조 카운트는 0보다 크다. 일단 0으로 떨어지면, 오브젝트는 메모리를 다른 오브젝트가 사용할 수 있도록 “해제” 하는 특정한 할당 해제 함수를 갖는다.
하지만 메모리를 “해제” 한다는 것은 무엇을 의미하며, 다른 물체들은 어떻게 그것을 사용하는지 CPython의 메모리 관리에 대해 살펴보자.
CPython의 메모리 관리
앞서 언급했듯이 물리적 하드웨어에서 CPython까지 추상화 계층이 있다. 운영 체제(OS)는 물리적 메모리를 추상화하고 애플리케이션(파이썬 포함)이 액세스할 수 있는 가상 메모리 계층을 생성한다.
OS별 가상 메모리 관리자는 Python 프로세스를 위해 메모리 덩어리를 잘라낸다. 아래 이미지의 더 어두운 회색 상자는 현재 Python 프로세스에서 소유한다.
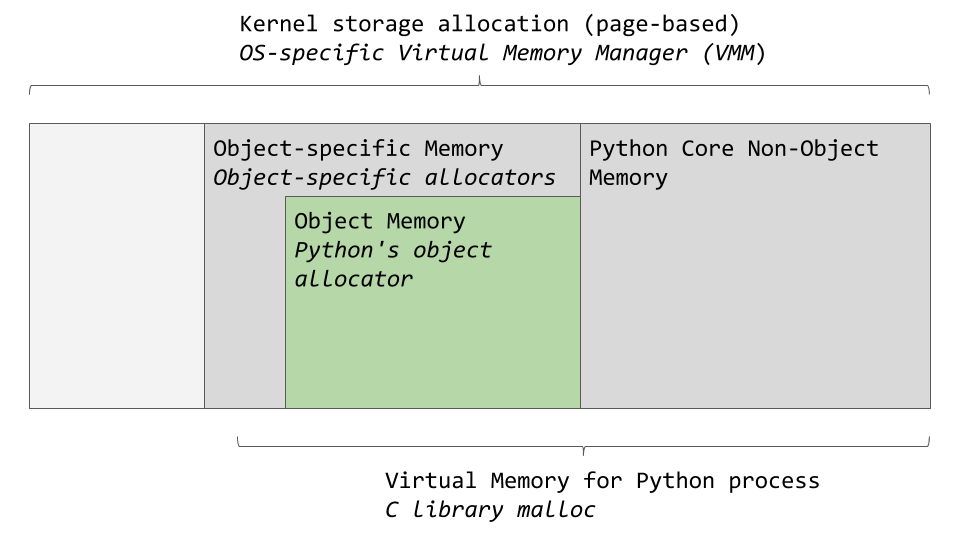
파이썬은 내부용 메모리와 비객체 메모리를 위해 메모리의 일부를 사용한다. 나머지 부분은 객체 스토리지(int, dict 등) 전용이다. 위 이미지는 매우 단순화 되어있는 이미지다. 전체를 보고싶길 원한다면 이 모든 메모리 관리가 이루어지는 CPython 소스 코드를 확인할 수 있다.
CPython은 객체 메모리 영역 내에서 메모리를 할당하는 객체 할당자를 가지고 있다. 이 객체 할당기는 대부분의 마법이 일어나는 곳이다. 새 개체에 공간을 할당하거나 삭제해야 할 때마다 호출된다.
일반적으로 list 및 int와 같은 Python 개체에 대한 데이터를 추가하고 제거하는 작업은 한 번에 너무 많은 데이터를 포함하지 않는다. 따라서 할당기의 설계는 한 번에 적은 양의 데이터에 대해 잘 작동하도록 조정된다. 또한 절대적으로 필요할 때까지 메모리를 할당하지 않는다.
소스 코드의 코멘트는 할당자를 “작은 블록들을 위한 빠르고 특별한 목적의 메모리 할당자"로 보여지게 하고 있다. 이 경우, malloc는 메모리 할당을 위한 C의 라이브러리 함수이다.
이제 CPython의 메모리 할당 전략을 살펴보자. 먼저, 세 가지 주요 부분과 그것들이 어떻게 서로 연관되어 있는지에 대해 알아보자.
영역은 메모리의 가장 큰 덩어리이며 메모리의 페이지 경계에 정렬된다. 페이지 경계는 운영 체제가 사용하는 고정 길이 연속 메모리 청크의 가장자리이다. 파이썬은 시스템의 페이지 크기가 256KB라고 가정한다.
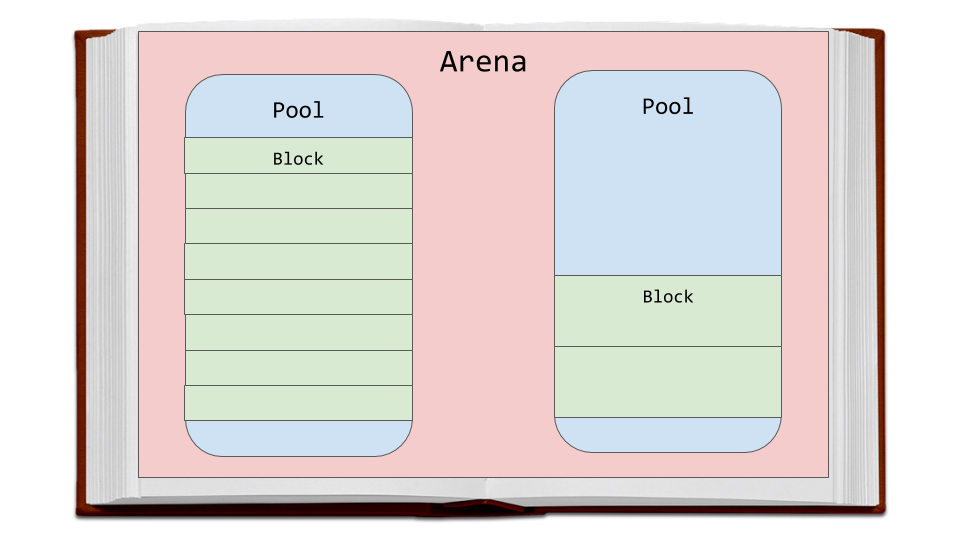
영역 내에는 하나의 가상 메모리 페이지(4 킬로바이트)인 풀이 있다. 이것들은 우리 책의 비유에 나오는 페이지와 같다. 이러한 풀은 더 작은 메모리 블록으로 분할된다.
지정된 풀의 모든 블록은 동일한 “size class” 이다. 크기 클래스는 요청된 데이터의 양에 따라 특정 블록 크기를 정의한다. 아래 차트는 소스 코드 주석에서 직접 가져온 것이다.
| Request in bytes | Size of allocated block | Size class idx |
|---|---|---|
| 1-8 | 8 | 0 |
| 9-16 | 16 | 1 |
| 17-24 | 24 | 2 |
| 25-32 | 32 | 3 |
| 33-40 | 40 | 4 |
| 41-48 | 48 | 5 |
| 49-56 | 56 | 6 |
| 57-64 | 64 | 7 |
| 65-72 | 72 8 | |
| … | … | … |
| 497-504 | 504 | 62 |
| 505-512 | 512 | 63 |
예를 들어, 42바이트가 요청되면 데이터는 48바이트 블록 크기에 배치된다.
풀
풀은 단일 크기 클래스의 블록으로 구성 된다. 각 풀은 동일한 크기 클래스의 다른 풀과 이중 링크된 목록을 유지한다. 이러한 방식으로 알고리즘은 주어진 블록 크기에 대해 사용 가능한 공간을 쉽게 찾을 수 있다.
사용된 풀 목록은 각 크기 클래스의 데이터에 사용할 수 있는 공간이 있는 모든 풀을 추적한다. 지정된 블록 크기가 요청되면 알고리즘은 사용된 풀 목록에서 해당 블록 크기에 대한 풀 목록을 확인한다.
풀 자체는 사용됨, 가득 찼음 또는 비어 있음의 세 가지 상태 중 하나여야 한다. 사용된 풀에는 데이터를 저장할 수 있는 블록이 있다. 전체 풀의 블록은 모두 할당되고 데이터를 포함한다. 빈 풀에는 저장된 데이터가 없으며 필요한 경우 블록의 모든 크기 클래스를 할당할 수 있다.
사용 가능한 풀 목록은 비어 있는 상태의 모든 풀을 추적한다. 하지만 언제 빈 풀이 사용될까?
코드에 8바이트 메모리 청크가 필요하다고 가정해보자. 8바이트 크기 클래스의 사용된 풀에 풀이 없는 경우 8바이트 블록을 저장하기 위해 새 빈 풀이 초기화된다. 그러면 이 새 풀이 사용된 풀 목록에 추가되어 이후 요청에 사용할 수 있다.
메모리가 더 이상 필요하지 않을 때에는 풀이 일부 블록을 해제한다. 해당 풀은 해당 크기 클래스의 사용된 풀 목록에 다시 추가된다.
이제 이 알고리즘을 사용하여 풀이 이러한 상태(및 메모리 크기 클래스) 사이에서 어떻게 자유롭게 이동할 수 있는지 볼 수 있다.
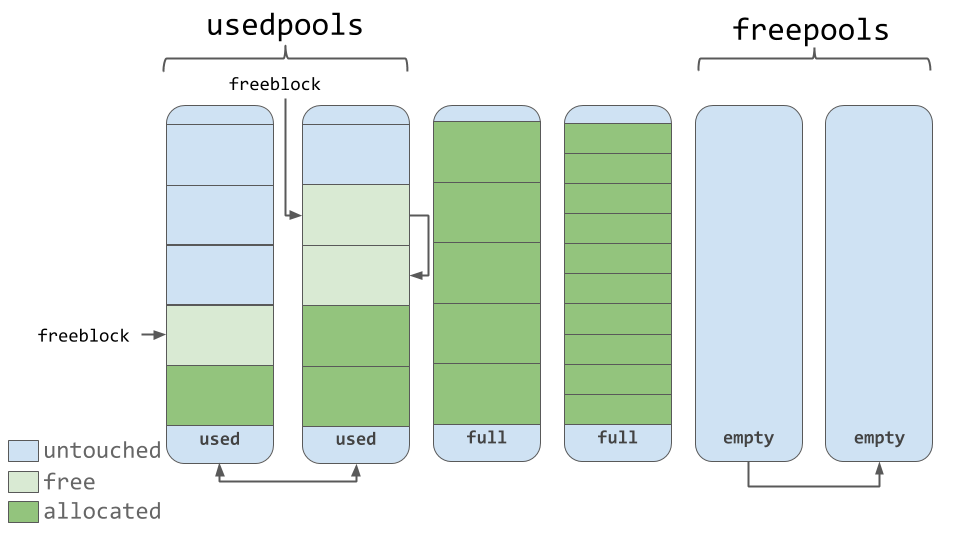
위의 다이어그램에서 볼 수 있듯이 풀에는 “사용 가능한” 메모리 블록에 대한 포인터가 포함되어 있다. 작동하는 방식에는 약간의 뉘앙스가 있다. 소스 코드의 코멘트에 따르면, 이 할당자는 “모든 레벨(아레나, 풀, 블록)에서 실제로 필요할 때까지 메모리 조각을 만지지 않도록 노력한다"라고 되어있다.
즉, 풀에는 3개 상태의 블록이 있을 수 있다. 이러한 상태는 다음과 같이 정의할 수 있다.
- untouched: 할당되지 않은 메모리 부분
- free: 할당되었지만 나중에 CPython에 의해 “free"로 만들어졌고 더 이상 관련 데이터를 포함하지 않는 메모리
- allocated: 실제로 관련 데이터를 포함하는 메모리 부분
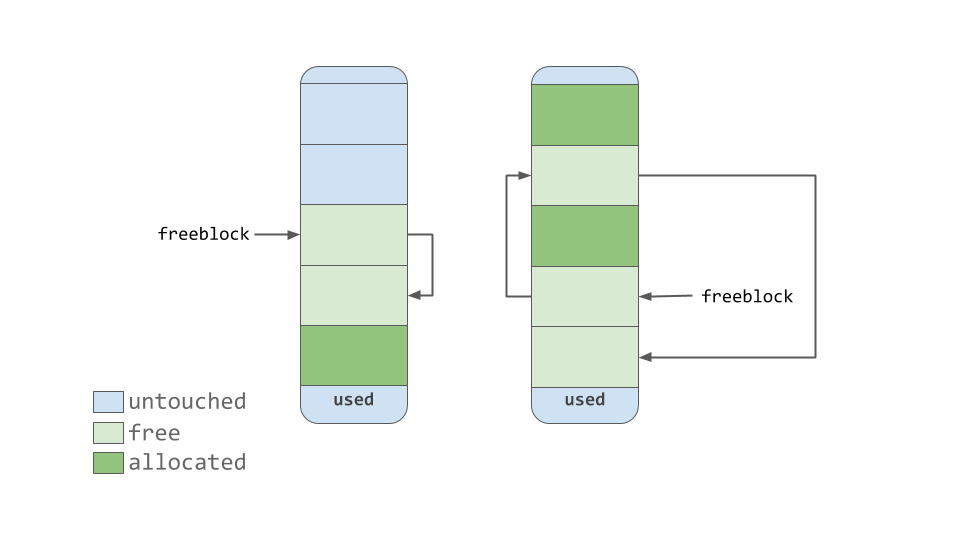
free 블록 포인터는 메모리의 free 블록의 단일 링크된 목록을 가리킨다. 즉, 데이터를 저장할 수 있는 위치 목록이다. 사용 가능한 블록이 더 필요한 경우 할당자는 풀에서 일부 변경되지 않은 블록을 가져온다.
메모리 관리자가 블록을 “free"로 만들 때, 이제 비어 있는 블록은 해제 블록 목록의 맨 앞에 추가된다. 실제 목록은 첫 번째 좋은 다이어그램처럼 연속된 메모리 블록이 아닐 수 있다. 오히려 아래 다이어그램과 비슷할 수 있다.
아레나
아레나에는 풀이 있다. 이러한 풀은 사용하거나, 가득 채우거나, 비워 둘 수 있다. 그러나 아레나 자체는 풀만큼 명시적인 상태를 가지고 있지 않는다.
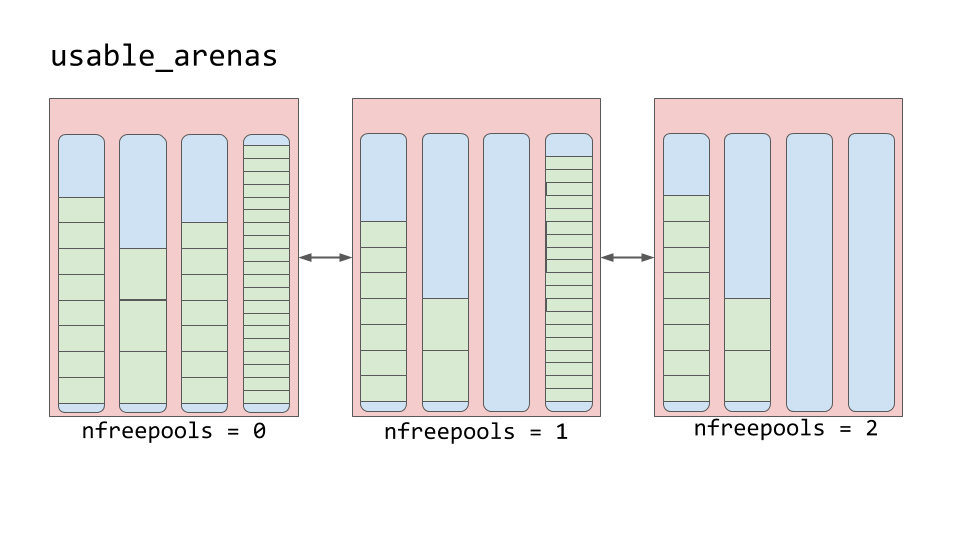
대신 아레나는 available_arenas라고 불리는 이중 연결 리스트로 구성된다. 목록은 사용 가능한 사용 가능한 풀의 수에 따라 정렬된다. free pool이 적을수록 아레나의 목록 맨 앞에 위치한다.
새로운 데이터를 배치할 가장 많은 데이터가 있는 경기장을 선택한다는 것을 의미한다. 하지만 왜 위치는 반대일까? 사용 가능한 공간이 가장 많은 곳에 데이터를 배치하는 것은 어떨까?
우리가 진짜로 메모리를 해제 시킨다는 착각을 하기 때문이다. 여러분은 제가 “free"라는 말을 꽤 많이 인용해서 말하고 있다는 것을 알수 있다. 그 이유는 블록이 “free"로 간주될 때, 그 메모리는 실제로 운영 체제에 해제되지 않기 때문이다. 파이썬 프로세스는 할당 상태를 유지하며 나중에 새 데이터에 사용될 것이다. 실제로 메모리를 확보하면 운영 체제에서 사용할 수 있다.
아레나는 진짜로 해제될 수 있는 유일한 것이다. 그래서 비어있는 것에 더 가까운 아레나가 더 비어있을 수 있도록 해야 한다. 이렇게 하면 해당 메모리 덩어리가 정말로 해제되어 파이썬 프로그램의 전체 메모리 공간을 줄일 수 있다.
결론
메모리 관리는 컴퓨터 작업에 필수적인 부분이다. Python은 좋든 나쁘든 거의 모든 것을 뒤에서 처리한다.
이 글에서는 우리는 다음과 같은 것을 배웠다.
- 메모리 관리란 무엇이며 왜 중요한가
- 기본 파이썬 구현인 CPython이 C 프로그래밍 언어로 작성되는 방법
- CPython의 메모리 관리에서 데이터 구조와 알고리즘이 함께 작동하여 데이터를 처리하는 방법
Python은 컴퓨터로 작업하는 많은 세부적인 사항들을 추상화한다. 이렇게 하면 모든 바이트가 어떻게 그리고 어디에 저장되는지에 대한 걱정 없이 코드를 개발할 수 있는 더 높은 수준의 작업을 수행할 수 있다.